
RAG System Evaluation: Measure What Matters Before Production
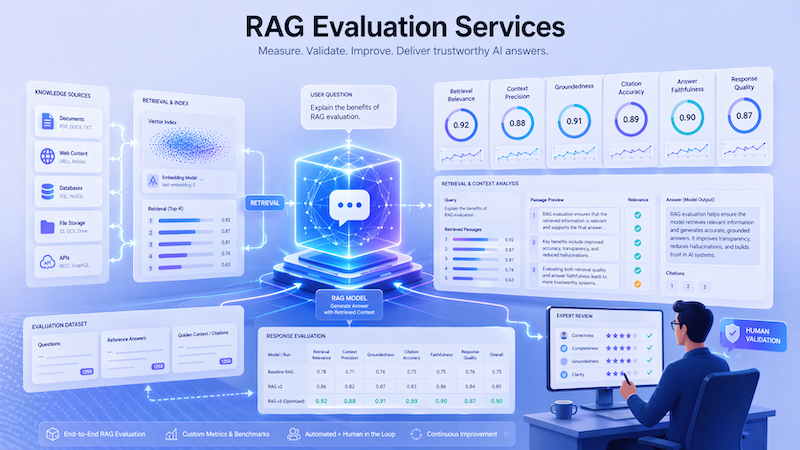
RAG Evaluation Services
Built for AI teams running RAG systems in production or preparing to ship them. You get structured evaluation across the full pipeline, retrieval quality, context relevance, groundedness, faithfulness, and answer utility, delivered by reviewers trained on RAG-specific failure modes and supported by calibrated inter-annotator agreement on every campaign.
End-to-end evaluation across retrieval and generation: context precision, recall, groundedness, faithfulness, relevance.
Reviewers trained on RAG failure modes: retrieval drift, hallucinated citations, out-of-context grounding, partial answers.
Integration with your eval stack: Argilla, LangSmith, Braintrust, Ragas, custom pipelines, or raw JSONL exports.
Retrieval-augmented generation solves the hallucination problem in theory and creates new failure modes in practice. Real RAG systems fail in ways that isolated LLM evaluation cannot detect: retrieval returns irrelevant context, generation fabricates citations that look legitimate, partial grounding creates answers that are half-supported and half-invented, and multi-turn interactions accumulate errors across the conversation. Standard benchmarks do not catch most of this.
DataVLab provides RAG evaluation services for engineering teams who need reliable measurement of their full pipeline. Our campaigns combine retrieval evaluation, groundedness verification, answer quality assessment, and failure mode analysis, delivered by reviewers trained on RAG-specific failure patterns. You get actionable findings linked to specific components: embedding model, chunking strategy, reranker, prompt template, generation parameters.
Our methodology evaluates retrieval and generation as a coupled system rather than two independent components. Every campaign starts with a representative query set covering your actual production distribution, including edge cases, out-of-scope queries, ambiguous questions, and adversarial prompts. Reviewers evaluate each example across multiple dimensions: was the retrieved context relevant, was it sufficient, was it ranked correctly, was the answer grounded, was it faithful to the context, did it address the query, did it meet domain-specific quality standards.
Results are structured for engineering action: failure mode taxonomy with frequency counts, per-component attribution where possible, reproduction data for each flagged example, and recommendations prioritized by impact. For teams using evaluation frameworks like Ragas, TruLens, or custom pipelines, we can align our human judgments with your existing metric definitions to calibrate automated evaluation against expert review.
RAG evaluation serves different engineering needs at different stages. Pre-production evaluation helps teams validate architecture choices: which embedding model, what chunk size, which reranker, how many retrieved passages to include. Production monitoring catches drift as document corpora grow, user query patterns evolve, or model versions change. Incident-driven evaluation helps diagnose specific failure patterns surfaced in production. A/B evaluation compares candidate configurations with statistical rigor before rollout.
We support teams building RAG for enterprise search, internal knowledge assistants, customer support agents, legal and medical document analysis, technical documentation, and specialized research tools. Campaign scope adapts to the engineering question: quick pilot evaluations to validate a hypothesis, comprehensive benchmarking suites for architecture decisions, or ongoing monitoring for production systems.
RAG evaluation quality depends on reviewers who actually understand what they are evaluating. Our RAG evaluator network includes reviewers trained specifically on RAG failure modes, information retrieval concepts, and the distinction between generation errors and retrieval errors. For domain-specific systems, we add reviewers with relevant expertise: legal professionals for legal RAG, medical professionals for clinical RAG, technical experts for engineering documentation RAG.
We integrate with whatever stack you are using. Evaluations can run in Argilla, Label Studio, LangSmith, Braintrust, or your custom evaluation tool. Results export in formats compatible with Ragas, TruLens, DeepEval, and common evaluation frameworks. For teams with strict data constraints, we offer EU-only reviewer teams and on-premise evaluation setups where data cannot leave your infrastructure.
How DataVLab Evaluates RAG Systems Across the Pipeline
RAG systems fail in ways isolated LLM evaluation cannot detect. We evaluate retrieval and generation together, catching failures that only emerge from the interaction between components.

Retrieval Quality Evaluation
Context precision, recall, and ranking quality for retrieved passages
We evaluate retrieval quality at the passage level: whether retrieved chunks actually contain information relevant to answering the query, whether ranking reflects relevance, and whether critical context is missing. Results feed directly into embedding model selection, chunking strategy, and reranker tuning decisions.
Groundedness and Faithfulness Assessment
Checking whether answers actually derive from retrieved context
We verify that generated answers are grounded in the provided context rather than fabricated or pulled from parametric memory. Reviewers flag unsupported claims, partial grounding where only some statements are supported, and fabricated citations. Critical for any RAG system where users trust the source attribution.
Answer Relevance and Utility
Does the answer actually address what the user asked?
Beyond factual correctness, we evaluate whether answers address the actual intent of the query, provide the right level of detail, and give the user what they need to act. Retrieval can be perfect and grounding can be correct while the answer still misses the point.
Failure Mode Analysis
Systematic identification of recurring failure patterns
We classify every failure into a taxonomy of RAG failure modes: retrieval miss, irrelevant context, hallucinated citation, over-confident partial answer, refused-but-answerable query, context window overflow, and domain-specific patterns. This turns evaluation into actionable engineering priorities.
Multi-Turn and Conversational RAG Evaluation
Evaluating RAG in dialogue and follow-up contexts
For conversational RAG and chatbot deployments, we evaluate context handling across turns: whether the system correctly reuses retrieved context, retrieves new context when needed, handles follow-up clarifications, and maintains factual consistency across the conversation. Single-turn evaluation misses most of what matters here.
Domain-Specific RAG Evaluation
Expert evaluation for legal, medical, technical, and regulated content
For RAG systems in specialized domains, we mobilize reviewers with domain credentials who can evaluate whether the system correctly interprets technical content, handles domain-specific ambiguity, and produces answers that match the epistemic standards of the field. A generic reviewer cannot tell whether a legal citation is actually supported.
Discover How Our Process Works

Defining Project
Sampling & Calibration
Annotation
Review & Assurance
Delivery
Explore Industry Applications


We provide solutions to different industries, ensuring high-quality annotations tailored to your specific needs.
We provide high-quality annotation services to improve your AI's performances

Annotation & Labeling for AI
Unlock the full potential of your AI application with our expert data labeling tech. We ensure high-quality annotations that accelerate your project timelines.
LLM Evaluation Services
Human evaluation of large language models with expert reviewers, calibrated rubrics, and reliable inter-annotator agreement. EU-based teams for projects that require quality and sovereignty.
LLM Red Teaming Services
Adversarial evaluation of large language models by safety and domain experts. Jailbreaks, prompt injection, harmful outputs, hallucinations, and bias discovery for AI teams shipping production systems.
Model Benchmarking Services
Independent benchmarking of LLMs across domains, languages, and use cases to support vendor selection, procurement, and strategic AI decisions. Custom evaluation frameworks built around your actual requirements.
Preference Dataset Creation for RLHF & DPO
Custom preference datasets for RLHF, DPO, and reward model training. Pairwise rankings with rationales, calibrated reviewers, measurable inter-annotator agreement, and delivery in your training format.
LLM Data Labeling and RLHF Annotation Services
Human in the loop data labeling for preference ranking, safety annotation, response scoring, and fine tuning large language models.
FAQs
Here are some common questions we receive from our clients to assist you.
What does RAG evaluation measure and why is it different from standard LLM evaluation?
RAG evaluation measures the quality of the full retrieval-augmented generation pipeline, not just the generator in isolation. It tracks four distinct dimensions: context precision (are the most relevant chunks ranked first?), context recall (is all necessary information being retrieved?), faithfulness (does the generated answer stay grounded in retrieved context?), and answer relevancy (does the response address what the user actually asked?). Standard LLM evaluation tests generation quality given a fixed prompt. RAG evaluation tests the interaction between retrieval and generation, the failure modes that only emerge from the coupling of the two components.
What are the most common failure modes in production RAG systems?
Production RAG systems fail in six predictable patterns: retrieval miss (the relevant document was never surfaced), wrong ranking (the right document is retrieved at position 8 instead of position 1), wrong chunk boundary (the answer spans two chunks and gets fragmented), hallucination (the generator adds claims not supported by retrieved context), generator drift (the model partially ignores context in favor of training data), and the most dangerous pattern, low faithfulness with correct answers, where the model bypasses retrieval entirely and answers from training data. This last pattern appears to work until your knowledge base updates, at which point the model continues producing stale answers with confidence.
What is the RAGAS framework and how does it relate to RAG evaluation?
RAGAS is an open-source framework that provides reference implementations of the core RAG evaluation metrics: faithfulness, answer relevancy, context precision, and context recall. It is the conceptual standard for component-wise RAG evaluation and includes a synthetic dataset generator for creating initial golden datasets from your document corpus. RAGAS is best suited for exploration and metric familiarization. For production CI/CD integration, frameworks like DeepEval provide tighter engineering workflow integration. For production monitoring, Patronus and Langfuse add observability and bias detection. Most mature RAG evaluation programs use RAGAS for methodology and combine it with other tools for production use.
How do you build a golden dataset for RAG evaluation?
A golden dataset for RAG evaluation consists of 100 to 200 question-answer pairs that represent the actual distribution of your production workload. For each pair, you need the relevant source documents in your knowledge base clearly identified. Building it well requires three steps: generating a representative question set (from production logs, synthetic generation, or domain expert input), writing ground-truth answers that reflect expert standards, and validating source attributions so you know which documents should have been retrieved. Domain experts must be involved in validation, because questions that look realistic but lack accurate ground-truth answers produce misleading evaluation results.
What is faithfulness in RAG evaluation and what threshold should teams target?
Faithfulness measures how factually consistent a RAG-generated response is with the retrieved context. It is computed by extracting all claims from the response and checking each against the retrieved documents. The fraction of supported claims gives the faithfulness score, from 0 to 1. For production deployment, a faithfulness score of 0.75 or higher is the standard minimum threshold. Below 0.75, users will regularly encounter hallucinated claims in responses. Above 0.85, the model is reliably grounded. When faithfulness is low despite relevant context being retrieved, the fix is generator-side: stronger system prompts, lower temperature, or a model with better instruction following.
How much does LLM-judged RAG evaluation cost to run continuously?
With GPT-4o-mini as the evaluation judge, expect approximately $0.001 to $0.003 per test case across five metrics. A 200-question golden dataset costs under $1 per evaluation run, making it economically trivial to run on every CI/CD build. For production monitoring, the pattern most teams adopt is sampled evaluation: 1 to 5 percent of production traces randomly, plus 100 percent of low-confidence outputs, plus all outputs from new feature deployments during the first 48 hours. For European teams with sovereignty requirements, note that using a US-based judge model sends production data through US infrastructure. EU-sovereign judge models like Mistral are available as alternatives with some quality trade-off.






Custom service offering
Up to 10x Faster
Accelerate your AI training with high-speed annotation workflows that outperform traditional processes.
AI-Assisted
Seamless integration of manual expertise and automated precision for superior annotation quality.
Advanced QA
Tailor-made quality control protocols to ensure error-free annotations on a per-project basis.
Highly-specialized
Work with industry-trained annotators who bring domain-specific knowledge to every dataset.
Ethical Outsourcing
Fair working conditions and transparent processes to ensure responsible and high-quality data labeling.
Proven Expertise
A track record of success across multiple industries, delivering reliable and effective AI training data.
Scalable Solutions
Tailored workflows designed to scale with your project’s needs, from small datasets to enterprise-level AI models.
Global Team
A worldwide network of skilled annotators and AI specialists dedicated to precision and excellence.
Potential Today
Blog & Resources
Explore our latest articles and insights on Data Annotation



We are here to assist in providing high-quality data annotation services and improve your AI's performances