
Preference Datasets That Actually Improve Your Models
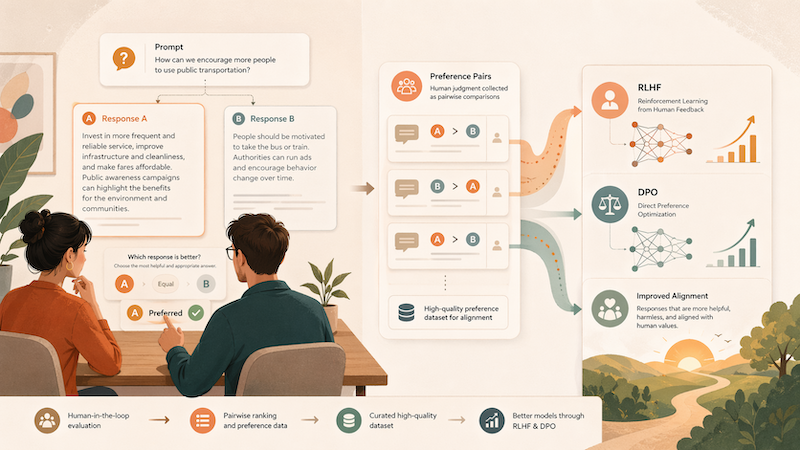
Preference Dataset Creation for RLHF & DPO
Built for teams fine-tuning and aligning language models who need preference data they can actually train on. You get custom pairwise ranking datasets with optional rationales, calibrated reviewers matched to your domain, and measurable inter-annotator agreement, delivered in the format your training pipeline expects (JSONL, Parquet, HuggingFace datasets, custom schemas).
Pairwise preference data built to your specification: response pairs, prompt distribution, rating schema, optional rationales.
Calibrated reviewers with measurable IAA, not anonymous crowd workers. Reliable signal for reward models and DPO.
Delivered in your training format: JSONL, Parquet, HuggingFace datasets, Anthropic HH format, custom schemas.
Preference data is the fuel for RLHF, DPO, and modern alignment methods. The quality of your preference dataset determines whether your reward model learns the behaviors you want or the artifacts of careless labeling. Low-agreement rankings, unrepresentative prompts, and unmotivated rationales produce reward models that game the wrong signal. Teams that invest in preference data quality see measurably better alignment outcomes than teams optimizing only on volume.
DataVLab builds preference datasets for AI teams fine-tuning foundation models, training custom reward models, running DPO alignment, or experimenting with newer preference optimization methods. Our datasets are built to your specification on prompt distribution, rating schema, reviewer profile, and output format. You get measurable quality metrics (inter-annotator agreement, rationale completeness, prompt coverage) alongside the raw data.
Every preference dataset project starts with specification. What prompt distribution matches your use case? What rating schema will your training pipeline use (binary preferences, Likert scales, multi-dimensional ratings)? What reviewer profile do you need (generalist, multilingual, domain expert)? What inter-annotator agreement target is realistic for your task? What output format does your training code expect? We calibrate these decisions with your team before starting production, because mistakes at this stage compound through the entire dataset.
Production runs with multi-stage quality control: calibration rounds on shared examples, consensus mechanisms on disagreements, expert adjudication on contested items, continuous guideline refinement as edge cases emerge, and sampled review by senior reviewers. Every dataset ships with full metadata, quality reports, and the raw per-reviewer judgments so you can do your own analysis or filter aggressively if needed.
Preference datasets serve different training goals. RLHF reward model training typically needs tens of thousands of pairwise rankings covering a broad capability distribution. DPO training can work with smaller datasets if the quality is high and the prompt distribution is well-designed. Research projects often need smaller, highly-curated datasets for specific hypotheses. Production alignment projects need ongoing data generation tied to observed production failure modes.
We support teams across these use cases: foundation model developers building general-purpose reward models, enterprise AI teams fine-tuning specialist models on proprietary domains, research groups experimenting with new preference optimization methods, and safety teams building datasets for specific failure modes or capability evaluation. Dataset scope ranges from 500 pairs for targeted experiments to 100,000+ pairs for full reward model training.
Format matters. Your preference dataset should arrive in exactly the structure your training code expects, not in a format that requires a week of preprocessing before you can actually train. We deliver in JSONL with configurable schemas, Parquet for large datasets, HuggingFace datasets format, Anthropic HH-style structured data, and custom schemas defined by your team. Integration with training frameworks (TRL, Axolotl, LlamaFactory, custom pipelines) is a standard part of delivery.
For teams with strict data requirements, we offer EU-only reviewer networks, GDPR-compliant data handling, and on-premise or isolated-cloud evaluation environments where preference data cannot leave your infrastructure. Signed NDAs with every reviewer. Full traceability on provenance, reviewer profile (without identifying information), and quality metrics for audit and reproduction.
What We Build for RLHF, DPO, and Reward Model Training
Preference dataset quality determines what your reward model actually learns. We build datasets designed to produce useful training signal, not just volume.

Pairwise Preference Datasets
The foundation of RLHF, DPO, and reward model training
We produce pairwise preference datasets where reviewers rank pairs of model responses on defined criteria. Optional rationales explain why one response is preferred. Typical outputs range from a few thousand pairs for targeted fine-tuning to tens of thousands for full reward model training. Delivered with full metadata on reviewer IDs, timing, and agreement scores.
Constitutional AI and Principle-Based Rankings
Rankings grounded in explicit principles or policies
For teams using Constitutional AI, policy-driven alignment, or custom rating constitutions, we train reviewers on your specific principles and produce rankings that reflect those principles consistently. Useful when standard helpfulness-and-harmlessness rankings miss your actual alignment goals.
Multi-Dimensional Rating Datasets
Rankings across multiple criteria for fine-grained training signal
Instead of or alongside binary preferences, we produce multi-dimensional ratings: helpfulness, factuality, safety, tone, reasoning quality, instruction following. Useful for multi-objective reward models or for teams experimenting with fine-grained preference signal beyond single pairwise comparisons.
Rejected Response Generation and Critiques
Building training data for SFT and critique fine-tuning
We produce preferred-rejected response pairs where rejected responses are realistic failure modes (not random baseline outputs), optionally with human-written critiques explaining the failure. Supports supervised fine-tuning, critique-based training, and iterative refinement pipelines beyond pure RLHF.
Domain-Specific Preference Data
Expert-ranked datasets for specialized model fine-tuning
For teams fine-tuning LLMs on specialized domains (medical, legal, financial, technical), we mobilize domain experts to produce preference data where expertise actually matters. A generic reviewer cannot reliably rank medical advice or legal reasoning. The dataset is only as good as the reviewers who built it.
Prompt Distribution Design and Coverage
Representative prompt sets that cover your actual use case
We help teams design prompt distributions that cover their actual production use case: capability categories, difficulty levels, edge cases, adversarial inputs, multi-turn contexts. A preference dataset on the wrong prompts will not improve the behaviors you actually care about.
Discover How Our Process Works

Defining Project
Sampling & Calibration
Annotation
Review & Assurance
Delivery
Explore Industry Applications






We provide solutions to different industries, ensuring high-quality annotations tailored to your specific needs.
We provide high-quality annotation services to improve your AI's performances

Annotation & Labeling for AI
Unlock the full potential of your AI application with our expert data labeling tech. We ensure high-quality annotations that accelerate your project timelines.
LLM Evaluation Services
Human evaluation of large language models with expert reviewers, calibrated rubrics, and reliable inter-annotator agreement. EU-based teams for projects that require quality and sovereignty.
LLM Red Teaming Services
Adversarial evaluation of large language models by safety and domain experts. Jailbreaks, prompt injection, harmful outputs, hallucinations, and bias discovery for AI teams shipping production systems.
Model Benchmarking Services
Independent benchmarking of LLMs across domains, languages, and use cases to support vendor selection, procurement, and strategic AI decisions. Custom evaluation frameworks built around your actual requirements.
RAG Evaluation Services
End-to-end evaluation of retrieval-augmented generation systems across retrieval quality, context relevance, groundedness, faithfulness, and answer utility. For teams shipping RAG to production.
LLM Data Labeling and RLHF Annotation Services
Human in the loop data labeling for preference ranking, safety annotation, response scoring, and fine tuning large language models.
FAQs
Here are some common questions we receive from our clients to assist you.
What is a preference dataset and how is it used in RLHF and DPO training?
A preference dataset consists of pairs of model responses to the same prompt, annotated by human reviewers who indicate which response they prefer and why. In RLHF (Reinforcement Learning from Human Feedback), these pairs train a reward model that learns to predict human preferences. The reward model then guides policy optimization via PPO. In DPO (Direct Preference Optimization), the preference pairs are used directly as a classification objective without an explicit reward model, simplifying the training pipeline. The quality of the preference dataset determines the quality of alignment, and low-agreement rankings, unrepresentative prompts, and poorly motivated preferences produce reward models that optimize for the wrong signal.
How many preference pairs are needed for RLHF or DPO training?
For general alignment using RLHF, reward model training typically requires tens of thousands of preference pairs covering a broad capability distribution. For DPO, quality often matters more than volume, and well-constructed datasets of 10,000 to 50,000 pairs can outperform larger datasets with lower annotation quality. For domain-specific fine-tuning (legal tone adjustment, medical formality, brand voice calibration), 5,000 to 20,000 carefully selected pairs targeting the relevant capability dimensions is a reasonable starting point. Research experiments can work with 500 to 2,000 high-quality pairs for testing specific hypotheses.
What inter-annotator agreement target should preference annotation achieve?
For RLHF preference annotation, the target Krippendorff's alpha is typically 0.60 to 0.75. This is intentionally lower than objective annotation tasks because preference annotation is inherently subjective, and the disagreement between annotators captures real human variance that the reward model should learn from. Forcing higher agreement through overly constrained guidelines removes the natural preference signal. Below 0.60 indicates that annotators are not understanding the task or that guidelines need clarification. Above 0.85 suggests annotators are applying mechanical rules rather than genuine judgment, which limits the model's ability to learn nuanced preference patterns.
What is the difference between RLHF and DPO and which should teams use in 2026?
RLHF trains an explicit reward model from preference data and uses PPO to optimize the policy against it. DPO eliminates the reward model, directly optimizing on preference pairs using a classification loss. DPO is simpler, cheaper (50-70% lower compute cost), and more reproducible, making it the right default for most production alignment work. RLHF retains genuine advantages for specific scenarios: multi-objective optimization requiring dynamic trade-offs between competing objectives, federated deployment with privacy-preserving feedback collection, and workloads where the preference signal is sparse. The most sophisticated 2026 alignment pipelines use DPO for the bulk of alignment work and selective RLHF for specific refinement stages.
What annotation format does DataVLab use for preference datasets?
DataVLab delivers preference datasets in the format your training pipeline expects. Standard formats include JSONL with configurable schemas, Parquet for large datasets, HuggingFace datasets format, Anthropic HH-style structured data, and custom schemas defined by your team. Each dataset ships with full metadata including reviewer IDs (anonymized), timestamps, per-item agreement scores, and the raw per-reviewer judgments alongside the aggregated labels. This gives your team the flexibility to apply custom aggregation logic or filter aggressively on agreement scores if needed.
Why does preference data quality matter more than dataset size?
A reward model learns exactly what the preference data teaches it. If annotators are inconsistent, the reward model learns noise. If the prompt distribution does not cover the behaviors you want to improve, the reward model has no signal to learn from. If low-quality rejected responses are too obviously bad, the model cannot learn the subtle distinctions that actually matter in production. High-quality preference data, with calibrated annotators, representative prompts, meaningful chosen-rejected contrasts, and documented inter-annotator agreement, produces measurably better alignment outcomes than larger datasets produced with less care. Volume without quality compounds the wrong signal at scale.






Custom service offering
Up to 10x Faster
Accelerate your AI training with high-speed annotation workflows that outperform traditional processes.
AI-Assisted
Seamless integration of manual expertise and automated precision for superior annotation quality.
Advanced QA
Tailor-made quality control protocols to ensure error-free annotations on a per-project basis.
Highly-specialized
Work with industry-trained annotators who bring domain-specific knowledge to every dataset.
Ethical Outsourcing
Fair working conditions and transparent processes to ensure responsible and high-quality data labeling.
Proven Expertise
A track record of success across multiple industries, delivering reliable and effective AI training data.
Scalable Solutions
Tailored workflows designed to scale with your project’s needs, from small datasets to enterprise-level AI models.
Global Team
A worldwide network of skilled annotators and AI specialists dedicated to precision and excellence.
Potential Today
Blog & Resources
Explore our latest articles and insights on Data Annotation




We are here to assist in providing high-quality data annotation services and improve your AI's performances